https://therealmjp.github.io/posts/ten-years-of-d3d12/
Ten Years of D3D12
For those of us that have been using it from the start, it can be hard to believe that Direct3D 12 has been around for ten years now. Windows 10 was released on July 29th 2015, and D3D12 has been with us ever since. While it’s true that this is the longe
therealmjp.github.io
- Direct3D 12를 처음부터 사용해온 우리에게는 믿기 어렵지만, Direct3D 12가 이제 10년이 되었습니다. Windows 10은 2015년 7월 29일에 출시되었고, D3D12는 그때부터 우리와 함께해왔습니다. 주요 D3D 버전 업데이트 사이에서 가장 긴 기간이 지난 것은 사실이지만, API가 정적으로 유지되었다고 말하는 것은 공정하지 않습니다. 오히려 D3D12는 새로운 인터페이스, 함수, 그리고 shader model의 꾸준한 업데이트를 받아왔습니다. 이러한 업데이트에는 DXR이나 Work Graphs와 같이 많은 언론의 관심과 주목을 받은 매우 주요한 기능들이 포함되어 있습니다. 하지만 개발자의 삶을 더 쉽게 만들어줄 수 있는 작은 기능들과 편의성 개선 업데이트들도 많이 있었습니다. 또한 shader 언어로서의 HLSL도 꾸준히 업데이트되어 왔으며, 그 중 일부는 상당히 혁신적이었습니다. 본격적으로 살펴봅시다! 원하시는 부분으로 건너뛰고 싶으시면 아래의 목차를 자유롭게 사용하세요.
-
- Additions To the Core D3D12 API
- Programmable Sample Points
- View Instancing
- Depth Bounds Test
- Variable Rate Shading
- Relaxed Format Casting
- Directly Writing To Block-Compressed Formats
- Writable R9G9B9E5 Textures
- WriteBufferImmediate and OpenExistingHeapFromAddress
- GPU Upload Heaps
- ExecuteIndirect Incrementing Constant
- Sampler Feedback
- Tight Resource Alignment
- Render Passes
- Enhanced Barriers
- Ray Tracing
- Mesh Shaders
- Work Graphs
- New Shader Features
- Wave Ops
- Quad Ops
- 16-bit floats and integers
- Barycentrics
- Shader Libraries & Linking
- Helper Lane Detection And Control
- Dynamic Resources (ResourceDescriptorHeap)
- WaveSize
- Derivatives In Compute
- 64-Bit Atomics and Atomic CAS For Floats
- Raw Texture Gather
- Writable MSAA Textures
- SampleCmpLevel
- ByteAddressBuffer Types Load and Store
- SV_StartVertexLocation + SV_StartInstanceLocation
- Enums
- Templates
- Operator Overloading
- Bitfields
- C++-Style Function Overloading and For Loop Scoping
- Developer Workflow Enhancements
- What’s Changed For Me Personally
- Conclusion
- Additions To the Core D3D12 API
-
- 최근 지나간 10주년을 맞아, D3D12가 출시된 이후 D3D12의 세계에서 무엇이 변화했는지 되돌아보기에 좋은 시기라고 생각했습니다. 그 후, API와 프로그래밍 언어가 발전함에 따라 제 코딩 및 개발 스타일이 어떻게 진화했는지 개인적으로 변화한 것들을 되돌아보는 것도 흥미로울 것 같았습니다. 어떤 경우에는 API 개선 덕분에 상당히 간소화할 수 있었고, 다른 경우에는 단지 새로운 방식을 받아들였습니다.
Additions To the Core D3D12 API
Programmable Sample Points
이것은 사용 사례가 매우 특수하고 MSAA가 더 이상 인기가 없기 때문에 일반적으로 사용되는 기능은 아닙니다. 간단히 말해서, "표준" sample이 제공하는 회전된 그리드 패턴을 사용하는 대신 자신만의 커스텀 MSAA subsample 위치를 제공할 수 있는 새로운 API를 추가합니다:

T이 API를 사용하면 단일 픽셀이 아닌 2x2 크기의 픽셀 사각형 영역 내 위치를 지정할 수 있습니다. 이를 통해 에일리어싱 특성을 변경하는 더 불규칙한 샘플링 패턴 을 구현할 수 있습니다. 적어도 MSAA에 여전히 관심이 있다면 말이죠. :)
다른 주요 사용 사례는 가변 속도 셰이딩의 소프트웨어 구현으로, Activision이 과거에 여러 차례 발표한 바 있습니다. 이것은 또한 제가 과거에 직접 시도해 본 적이 있는 분야이기도 합니다. 프로그래밍 가능한 샘플 포인트가 유용한 이유는 4x MSAA로 "하프 해상도" 뎁스 버퍼를 생성하고, 뎁스 서브샘플 위치를 풀 해상도 패스에 사용된 것과 정확히 일치시킬 수 있기 때문입니다. 물론 요즘에는 하드웨어 VRS라는 또 다른 옵션도 있습니다(곧 다룰 예정입니다!). 이로 인해 이 사용 사례는 상당히 틈새 시장이 되었습니다..
View Instancing
덜 흔히 사용되는 또 다른 기능은 뷰 인스턴싱입니다. 이 기능은 VR이나 3D를 위한 스테레오 렌더링을 쉽고 최적화되도록 시도하는 API 및 셰이더 메커니즘을 제공합니다. 작동 방식은 다음과 같습니다: 드로잉이 최대 4개의 뷰에 대해 N회 인스턴싱되며, 모든 셰이더에서 SV_ViewID 를 입력으로 받아 현재 렌더링 중인 뷰를 식별할 수 있습니다. 이를 통해 해당 뷰에 적합한 뷰 매트릭스와 투영 매트릭스를 선택하여 적용할 수 있습니다. 앱 측에서는 각 뷰를 서로 다른 뷰포트에 매핑할지, 아니면 배열 텍스처의 서로 다른 슬라이스에 매핑할지 지정합니다. 또한 앱 측에서 비트필드 마스크를 설정하여 필요 시 각 뷰별로 별도로 컬링할 수도 있습니다.
이론적으로 이 API는 올바르게 사용될 경우 다중 뷰로 브로드캐스팅하는 네이티브 기능을 일부 보유한 하드웨어에 이점을 제공할 수 있습니다. 제가 아는 한 실제로는 엔비디아의 GS(Graphics Core)에 탑재된 "뷰포트 브로드캐스트" 기능이 유일합니다. 실제로는 대부분의 애플리케이션이 SV_ViewID를 후속 파이프라인 단계에서 사용하기보다는 버텍스 셰이더에서 소비할 것으로 예상되므로, 이 기능이 실질적인 이점을 제공했는지는 확실하지 않습니다. AMD 역시 Tier 1 이상의 지원을 제공한 적이 없는데, 이는 화려한 기능이라기보다는 일종의 "드로 콜 레벨 루핑"이 이루어지고 있음을 의미합니다. 이 경우, 일반 인스턴싱과 정점 셰이더에서 출력되는 SV_RenderTargetArrayIndex/SV_ViewportArrayIndex를 사용하여 직접 처리하는 것이 더 나을 수 있습니다.
Depth Bounds Test
깊이 경계 테스트는 오래된 기능입니다… 너무 오래되어 처음에는 스텐실 섀도 속도 향상을 위해 추가되었죠. 둠 3가 새로 나왔을 때 기억나시나요? 다른 API에서는 다양한 방식으로 노출되었지만, D3D12가 나올 때까지 공식적으로 D3D에 추가되지는 않았습니다. 어쨌든 이제 유용하게 쓸 수 있다면 사용할 수 있게 되었습니다. 기본적으로 작동 방식은 다음과 같습니다. 명령 목록에서 최소 및 최대 깊이 값을 지정하여 "범위"를 설정합니다. 그런 다음 삼각형을 그릴 때 각 픽셀은 기존 깊이 값(래스터화 중인 삼각형의 깊이가 아님)을 확인하고, 해당 값이 제공된 범위 내에 있으면 깊이 테스트를 통과합니다.
이 기능이 아직도 어떤 용도로 쓰이는지 잘 모르겠네요… 일부 렌더러에서는 빛 경계 볼륨을 하나씩 래스터화하는 구식 디퍼드 렌더링에 사용한 걸로 알고 있습니다. 경계 상자로 래스터화되는 디퍼드 데칼도 같은 방식으로 혜택을 볼 수 있을 겁니다. PS3 시절부터 전해 내려오는 오래된 기법도 있는데, 디퍼드 캐스케이드 섀도우를 한 캐스케이드씩 렌더링할 때 깊이 범위를 캐스케이드 최소/최대 깊이로 설정한 후 전체 화면 삼각형을 그리는 방식입니다.
Variable Rate Shading

가변 음영 처리(Variable Rate Shading, 줄여서 VRS)는 필요하지 않은 부분에서 비용이 많이 드는 픽셀 셰이더 스레드를 줄이려는 기술입니다. 핵심은 '음영 처리 비율'을 선택하면 픽셀 셰이더가 N개 픽셀 중 1개 픽셀만 처리하도록 하는 것입니다. 장점은 별도의 반해상도 렌더 타깃에 그리는 경우와 달리 풀 해상도 깊이 테스트를 유지할 수 있다는 점입니다. VRS는 또한 셰이딩 비율을 매우 세밀하게 선택할 수 있게 해주어, 낮은 셰이딩 비율 콘텐츠와 풀 셰이딩 비율 콘텐츠를 혼합하는 것을 훨씬 쉽게 만듭니다. 이는 OIT를 사용하지 않을 때 특히 입자나 투명 객체에 중요할 수 있습니다. 왜냐하면 이들을 뒤에서 앞으로 순서로 그려야 하기 때문입니다. 별도의 하프 해상도 패스와 합성 작업은 많은 저해상도 패스를 도입하지 않고서는 드로우 기반 정렬을 불가능하게 만듭니다. 이는 결국 성능 이점을 상쇄하게 될 것입니다.
API를 통해 음영 비율을 3가지 방법으로 지정할 수 있습니다:
- 드로우당, 명령어 목록에서
- 각 프라이미티브별로, 버텍스 셰이더/메쉬 셰이더/지오메트리 셰이더에서 SV_ShadingRate 를 출력함으로써
- 화면 공간에서 타일 단위로, 셰이딩 레이트 텍스처(최대 16x16 타일 크기)를 생성하여
특히 타일 기반 셰이딩 비율은 이전 프레임의 콘텐츠를 분석하여 콘텐츠의 변동성에 기반한 최적화된 셰이딩 비율을 자동 생성하려는 경우 유용합니다. 반면 드로잉별 설정은 반해상도 투명 드로잉이나 파티클 드로잉을 수동으로 태깅하는 데 더 유용할 것입니다.
VRS를 사용할 때 주의해야 할 두 가지 주요 단점은 다음과 같습니다:
- 성능 향상은 예상만큼 크지 않을 수 있습니다. 하드웨어가 여전히 픽셀 셰이더를 2x2 쿼드로 실행해야 하며, 실행 전에 전체 웨이브를 채워야 하기 때문입니다.
- 저해상도 드로우나 타일은 실제 픽셀에 거친 픽셀 출력값을 그대로 전달하여 결과물을 효과적으로 포인트 샘플링합니다. 따라서 더 나은 품질을 얻으려면 추가적인 공간 필터링 및/또는 시간적 재구성을 적용하는 것이 좋습니다.
Relaxed Format Casting
이는 새로운 API 기능이라기보다는 "호환 가능한" 형식으로 여러 뷰를 생성할 때의 규칙을 완화한 것입니다. 초기 D3D12에서는 D3D11과 동일한 규칙이 적용되어, 여러 호환 형식으로 텍스처를 볼 경우 TYPELESS 형식의 텍스처 리소스를 생성해야 했습니다. 예를 들어 텍스처를 R16_UINT와 R16_UNORM 양쪽으로 볼 계획이라면 R16_TYPELESS를 사용해야 했습니다. 이는 미리 여러 형식으로 리소스를 볼지 여부를 알아야 하므로 다소 불편했습니다. 또한 드라이버가 텍스처를 정수형과 부동소수점 데이터로 동시에 볼 것이라고 가정해야 할 경우 특정 압축이나 최적화를 사용할 수 없어 성능 저하가 발생할 수 있습니다.
완화된 형식 캐스팅을 사용하면 더 이상 이 과정이 필요하지 않습니다: 리소스를 완전히 "유형 지정된" 상태로 생성한 후, 원하는 만큼 호환되는 뷰를 생성할 수 있습니다. 단점은 부동 소수점 형식과 비부동 소수점 형식 간에는 형변환이 불가능하다는 점입니다. 이는 TYPELESS를 사용할 때 발생할 수 있는 드라이버 최적화 비활성화 상황을 방지합니다. 특히 깊이 버퍼의 경우, SRV를 통해 깊이 텍스처를 읽어야 할 때 이전에는 TYPELESS를 사용해야 했으나 이제는 그렇지 않아도 된다는 점에서 매우 유용합니다.
Directly Writing To Block-Compressed Formats
역사적으로 GPU가 블록 압축 형식의 텍스처에 쓰기 작업을 수행할 수 있는 유일한 방법은 복사하는 것이었습니다. GPU에서 블록 압축을 수행할 수 있도록 하기 위해 D3D10에는 "백도어"가 추가되어, 동등한 UINT 형식(R32G32_UINT 또는 R32G32B32A32_UINT)의 1/4 너비 및 1/4 높이 텍스처에서 BC 형식 텍스처로 복사할 수 있게 되었습니다. 이는 중간 복사 단계 없이 최종 텍스처에 직접 쓰는 것이 더 빠를 것이므로 분명히 이상적인 방법은 아닙니다. 향상된 배리어(Enhanced Barriers, 후술 예정)의 일환으로 D3D12는 Vulkan을 따라잡아 UAV를 통해 BC 텍스처에 직접 쓰기 기능을 획득했습니다. 작동 방식은 Vulkan과 유사합니다: 텍스처를 생성할 때 "캐스팅 가능한 형식(castable formats)" 배열을 전달하면, 쓰기에 사용할 동등한 UINT 형식을 포함시킬 수 있습니다:
- R32G32_UINT (8 bytes per block) for BC1 and BC4
- R32G32B32A32_UINT (16 bytes per block) for BC2, BC3, BC5, BC6, and BC7
Writable R9G9B9E5 Textures
DXGI_FORMAT_R9G9B9E5_SHAREDEXP 은 흥미로운 형식입니다: R11G11B10_FLOAT 과 유사한 점은 텍셀당 4바이트로 양의 부동 소수점 RGB 값을 저장할 수 있으며, 지수 비트 수가 동일(5)하기 때문에 fp10/fp11/fp16과 동일한 유효 범위를 제공한다는 점입니다. 그러나 fp10/11과 달리 R9G9B9E5는 각 채널에 9개의 맨티사 비트를 할당합니다. 이는 R11G11B10의 6비트 또는 5비트보다 많은 양입니다. 따라서 더 높은 정밀도를 제공하며 특정 상황에서 눈에 띄는 밴딩 현상을 줄일 수 있습니다. 단점은 지수부가 3개 채널 간에 공유된다는 점입니다. 따라서 3개 채널 간의 전체 크기가 높은 상관관계를 가질 때 가장 효과적으로 작동합니다.
전통적으로 이 형식은 읽기 전용이었으며, GPU는 텍스처로 샘플링할 때 자동으로 디코딩할 수 있었지만 RTV 또는 UAV 쓰기를 위한 자동 인코딩 수단은 없었습니다. 유일한 방법은 R32_UINT를 사용하는 UAV를 통해 쓰기를 수행하고 직접 비트를 인코딩하는 것이었습니다. 이 새로운 기능을 통해 지원 가능한 GPU는 렌더 타깃이나 타입 UAV를 통해 DXGI_FORMAT_R9G9B9E5_SHAREDEXP 쓰기를 지원함을 표시할 수 있습니다.
현재 시점에서 이 기능에 대한 지원은 RDNA2 또는 그 이후 버전의 AMD GPU로 제한되는 것으로 보입니다.
WriteBufferImmediate and OpenExistingHeapFromAddress
D3D12 코드를 작성하다 보면 결국 GPU가 충돌하게 됩니다. 이런 상황이 발생했을 때, GPU가 작동을 멈추기 직전 어떤 작업을 수행 중이었는지에 대한 대략적인 정보라도 확보할 수 있다면 도움이 됩니다. WriteBufferImmediate 와 OpenExistingHeapFromAddress 는 "브레드크럼"을 구현하여 이러한 종류의 정보를 수집할 수 있도록 하는 한 쌍의 API입니다. 기본적으로 WriteBufferImmediate 를 사용하여 명령 목록 기록의 여러 지점에 일종의 신호 값을 기록합니다. 그런 다음 장치가 제거되면 OpenExistingHeapFromAddress 를 사용하여 CPU의 브레드크럼 버퍼에 액세스하고 이를 검사하여 마지막으로 기록된 브레드크럼을 파악합니다.
이 기능은 내부적으로 DRED에서도 사용되며, 이에 대해서는 나중에 자세히 설명하겠습니다.
GPU Upload Heaps
초보 D3D12 프로그래머들이 겪는 초기 어려움 중 하나는 전용 그래픽 카드가 CPU가 사용하는 "시스템 메모리(SysRAM)"와 별개로 자체적인 물리적 VRAM 풀을 보유한다는 사실을 다루는 것입니다. 전통적으로 VRAM은 베이스 주소 레지스터(BAR)를 통해 접근 가능한 256MB의 작은 영역을 제외하고는 CPU가 직접 접근할 수 없었습니다. 이로 인해 리소스를 어디에 배치할지, 그리고 SysRAM에서 VRAM으로 복사하기 위해 GPU를 어떻게 활용할지에 대한 어려운 선택이 발생합니다.
새로운 시스템과 그래픽 카드에는 "Resizable BAR"라는 기능이 탑재되어 있어 운영체제가 VRAM 전체를 CPU 주소 공간에 효과적으로 매핑할 수 있게 합니다. D3D12는 GPU 업로드 힙을 통해 이 기능을 제공합니다. 이는 힙 또는 커밋된 리소스를 생성할 때 사용할 수 있는 새로운 D3D12_HEAP_TYPE_GPU_UPLOAD 열거형 값으로, Map()을 사용하여 CPU 가상 주소 공간에 매핑할 수 있습니다. 이는 GPU 복사 없이도 CPU가 VRAM에 존재하는 리소스의 내용을 직접 업데이트할 수 있음을 의미합니다. CPU에서 업데이트하는 버퍼의 경우, 데이터 레이아웃이 선형이므로 memcpy를 사용하기만 하면 됩니다. 텍스처의 경우, 좀 더 복잡합니다. 텍스처는 불투명한 레이아웃을 사용하므로, 내용을 업데이트하려면 WriteToSubresource 를 사용해야 합니다.
AMD는 RDNA2 아키텍처에서 ReBAR 지원을 시작했으며, 엔비디아는 암페어 아키텍처에서 이를 지원하기 시작했습니다. 인텔의 전용 GPU는 모두 이를 지원합니다. 일반적으로 ReBAR를 사용하려면 UEFI 설정에서 활성화해야 합니다. GPU 업로드 힙은 커널 변경이 필요하기 때문에 안타깝게도 Windows 11에서만 사용할 수 있습니다.
ExecuteIndirect Incrementing Constant
ExecuteIndirect는 정말 훌륭합니다. 간접 드로잉, 간접 디스패치, 다중 드로잉/디스패치를 통합된 인터페이스로 묶어줍니다. 하지만 Vulkan에 비해 한 가지 큰 결점은 셰이더가 드로잉별 또는 메시별 데이터에 접근할 수 있는 "DrawID"가 없다는 점이었습니다. ExecuteIndirect는 명령 시그니처의 일부로 각 드로우에 대한 루트 상수를 설정하여 사용자가 직접 이를 구현할 수 있을 만큼 유연합니다. 하지만 이 방식은 드라이버 측에서 상당히 복잡한 작업을 수행해야만 예상대로 동작합니다. 반면 DrawID 생성은 많은 하드웨어가 기본적으로 지원할 수 있는 기능입니다.
증가 상수(대부분)는 드로우 또는 디스패치마다 증가하는 암시적 상수 버퍼 값을 셰이더에 전달함으로써 이 간극을 메웁니다. SV_DrawID 만큼 편리하지는 않지만, 그 역할을 수행합니다.
이 글을 작성하는 시점에서 엔비디아만이 티어 1.1 실행 간접 지원과 증분 상수(파스칼 아키텍처로 거슬러 올라가는 모든 하드웨어에서 지원됨)에 대한 지원을 보고하고 있습니다. AMD와 인텔도 언젠가는 따라잡을 것으로 예상됩니다.
Sampler Feedback
엔비디아 RTX 2000 시리즈(일명 튜링) 출시 당시를 기억하시는 분들은 '텍스처 공간 셰이딩' 지원 주장을 떠올리실 겁니다. 정말 멋져 보였지만, 실제로 구현된 것은 샘플러 피드백이었습니다. 기본적으로 이 기능은 UV 좌표와 텍스처 설명을 바탕으로 어느 텍셀(일정 수준의 세분화 범위 내)이 액세스되었는지 파악할 수 있게 해줍니다. 이를 통해 상당히 정밀한 데이터를 얻을 수 있으며, 이 데이터를 피드백 시스템의 일부로 활용하여 스파스 가상 텍스처의 레지던시(residence)를 결정하거나(또는 텍스처 공간 셰이딩을 위해 셰이딩해야 할 텍셀을 선택하는 데) 사용할 수 있습니다.
가장 큰 단점은 API가 상당히 복잡하다는 점입니다. 초기 불투명 피드백 데이터를 저장할 리소스를 설정해야 하고, 추가 디스크립터를 바인딩해야 하며, 셰이더에 피드백 생성을 추가해야 하고, 피드백 데이터를 읽기 가능한 형식으로 "해결"해야 하며, 마지막으로 CPU에서 읽으려면 다시 복사해야 합니다. 이 모든 과정을 거친 후에야 어떤 영역이 샘플링되었는지에 대한 정보를 확인할 수 있습니다. 제 경험상 셰이더에서 원자적 쓰기(atomic write)를 수행하는 것보다 훨씬 다루기 어렵고 비용도 더 많이 듭니다. 따라서 매우 정확한 피드백이 필요하지 않은 이상 권장하지 않을 것입니다.
엔비디아는 튜링 아키텍처 이상에서 이를 지원하며, AMD는 RDNA2+ 아키텍처 이상에서 지원합니다. 인텔은 Xe 아키텍처 이상에서 지원합니다.
Tight Resource Alignment
D3D12는 처음부터 리소스에 대해 고정된 정렬 요구사항을 적용하기로 결정했습니다. 이는 런타임에 장치 속성으로 정렬이 보고되는 Vulkan에 비해 단순합니다. 큰 단점은 D3D 정렬이 경우에 따라 훨씬 클 수 있어 많은 낭비를 초래한다는 점입니다. 특히 악명 높은 D3D12_DEFAULT_RESOURCE_PLACEMENT_ALIGNMENT 는 버퍼에 대해 64KB로 설정되어 있어, 작은 버퍼용 배치 리소스를 다수 생성할 경우 메모리 사용량이 급격히 증가할 수 있습니다.
"타이트 배치 리소스 정렬"을 사용하면 훨씬 더 작은 정렬 값을 지원하는 새로운 D3D12_RESOURCE_FLAG_USE_TIGHT_ALIGNMENT 플래그를 전달할 수 있습니다. 버퍼의 경우 정렬 범위가 8바이트에서 256바이트로 확대되었으며, 텍스처는 MSAA 미적용 시 8바이트에서 64KB(MSAA 적용 시 8바이트에서 4MB)까지 정렬이 가능합니다. 이로 인해 소규모 배치 버퍼 리소스의 활용성이 크게 향상되었습니다.
현재 이 기능은 아직 프리뷰 단계이며, 1.716.1 프리뷰 Agility SDK에서만 사용할 수 있습니다.
Render Passes
대상 GPU가 타일러인 경우 렌더 패스를 반드시 사용해야 합니다. 이는 OMSetRenderTargets 호출을 BeginRenderPass 및 EndRenderPass 호출 쌍으로 대체합니다. 중요한 점은 BeginRenderPass가 렌더 타깃 데이터의 수명에 대한 앱의 기대치와 이전 데이터를 보존해야 하는지 여부를 나타내는 여러 플래그를 받아들이는 것입니다. 이러한 플래그를 통해 타일러(예: Qualcomm의 Adreno 라인에 포함된 타일러)는 온칩 메모리 처리 방법에 대해 최적의 결정을 내릴 수 있으며, 상당한 대역폭을 소모하는 온칩 메모리 안팎으로 데이터를 로드하는 과정을 건너뛸 수도 있습니다.
Enhanced Barriers
D3D12와 Vulkan은 각자의 API에서 초기 장벽 노출 방식이 상당히 달라졌습니다. D3D12는 "리소스 상태" 추상화를 선택했는데, 여기서 장벽은 한 상태에서 다른 상태로의 "전환"을 나타내며 드라이버가 이를 통해 적절한 데이터 가시성과 동기화를 보장하기 위해 필요한 단계를 추론할 수 있게 합니다. 반면 Vulkan은 보다 명시적인 접근 방식을 선택했습니다. 스레드 동기화, 캐시 플러시 요구사항, 텍스처 데이터 변환 등이 모두 별도의 접근 전/후 쌍으로 표현되었습니다.
흥미로운 아이디어였을지 모르나, D3D12의 접근 방식은 실제로는 상당히 혼란스럽고 비효율적이었습니다. 모든 가시성 변경을 전환으로 표현하는 방식은 일부 프로그래머들에게 GPU가 내부적으로 실제로 수행하는 작업에 대한 잘못된 사고 모델을 심어주었고, 다른 경우에는 안전성을 보장하기 위해 드라이버가 불필요한 플러시를 삽입해야 하는 상황이 발생했습니다. 가장 심각한 문제는 리소스 상태의 "승격(promotion)"과 "감쇠(decay)" 개념이었습니다. 하드웨어 수준에서 보면 기본 개념은 사실 상당히 간단합니다: ExecuteCommandLists를 통해 명령어 목록 배치를 제출하면, 런타임은 해당 배치 완료 후 암묵적인 동기화와 캐시 플러시를 강제합니다. 이는 여러 ECL 배치에 걸친 종속성 때문에 동기화가 필요하지 않음을 의미합니다: 첫 번째 ECL 배치 이후 이미 전역 동기화/플러시가 수행되었으므로 다시 할 필요가 없습니다. 텍스처의 경우 미래 사용을 알지 못하면 암시적 레이아웃 변경이 불가능하므로, 여전히 기존처럼 배리어를 사용해야 합니다. 문제는 이 암묵적 동기화를 기존 배리어 시스템을 통해 노출하는 방식이 어색하고 복잡했다는 점입니다. 모든 것을 "리소스 상태"로 추상화하는 방식과 깔끔하게 매핑되지 않기 때문입니다. 암묵적 승격 및 감쇠 관련 문서가 복잡한 이유도 여기에 있습니다. 텍스처 레이아웃 변경을 유발하는 모든 경우를 배제하면서 특정 상황에서 허용되는 암묵적 상태 전환 방식을 설명해야 하기 때문입니다.
강화된 배리어는 본질적으로 Vulkan 방식을 채택합니다. 즉, 배리어 자체에 동기화(sync), 플러시(flush), 레이아웃(layout) 옵션이 포함됩니다. 초보자에게는 기존 배리어에 비해 처음 이해하기 어려울 수 있지만, 장기적으로는 훨씬 단순해진다고 생각합니다. ECL 배치에서 발생하는 암시적 동기화/플러시는 이제 향상된 배리어로 매우 쉽게 처리할 수 있습니다: 종속성이 ECL 배치를 가로지르는 경우 해당 작업 중 하나만 수행하는 배리어는 건너뛸 수 있지만, 레이아웃 전환 배리어는 여전히 발행해야 합니다. 향상된 배리어 사양에는 추가적인 이점도 명시되어 있습니다. 예를 들어, 이전에는 드라이버가 추가 플러시를 요구했던 상황을 피할 수 있습니다. 또한 이제 배리어의 일부로 리소스를 폐기할 수 있는데, 이는 추가 명령어와 배리어를 절약할 수 있는 매우 환영받는 편의 기능입니다.
Ray Tracing

DXR에 대해 여기서 설명할 필요는 거의 없을 것 같습니다. D3D12에 추가된 기능 중 가장 많이 홍보되고 잘 알려진 기능이기 때문입니다. 혹시 모르시는 분들을 위해 말씀드리면, DXR은 D3D12에 하드웨어 레이 트레이싱 지원을 제공합니다. 이 기능은 두 가지 방식으로 노출됩니다:
- DXR 1.0 DispatchRays 파이프라인에서는 RayGen, ClosestHit, Miss, AnyHit 또는 Intersection 셰이더를 거대한 "RTPSO"의 일부로 제공하는 매우 구조화된 설정을 얻을 수 있습니다. 이 설정으로 RayGen 셰이더(매우 단순화된 컴퓨트 셰이더와 유사)에서 광선을 추적한 다음, 해당 광선이 무엇에 충돌했는지(또는 충돌하지 않았는지)에 따라 GPU가 자동으로 올바른 셰이더를 호출합니다.
- DXR 1.1 RayQuery 파이프라인은 "인라인 트레이싱"이라고도 불리며, 기존 셰이더 유형에 하드웨어 레이 트레이싱 기능을 훨씬 더 직접적으로 노출합니다. 이 설정에서는 "RTPSO"나 "셰이더 테이블"이 필요하지 않으며, 루프의 일부로 쿼리를 실행한 후 교차 정보를 얻기만 하면 됩니다. 그 이후에는 히트에 대한 대응을 완전히 자유롭게 할 수 있으며, 히트 셰이더를 자동으로 호출하는 등의 기능은 없습니다.
두 방법 모두 장면에 대한 "가속 구조체"를 구축해야 합니다. 이 구조체에는 BVH 또는 하드웨어가 광선/삼각형 교차 가속을 위해 사용하는 형식이 포함됩니다. 이러한 가속 구조 구축은 GPU에서 수행되며, 메쉬 목록과 해당 위치 및 인덱스 데이터에 대한 포인터를 제공하여 시작해야 합니다. 이렇게 생성된 "하위 레벨 가속 구조"(BLAS)는 "상위 레벨 가속 구조"(TLAS)로 인스턴스화될 수 있으며, 이를 통해 동일한 메쉬를 메모리를 중복하지 않고 여러 위치에 복제할 수 있습니다. 또한 BLAS를 완전히 재구축하지 않고 단순한 TLAS만 재구축하여 메시를 이동시킬 수도 있습니다. 하지만 애니메이션/변형 가능한 메시는 훨씬 까다롭습니다… 프레임마다 위치가 이동함에 따라 BLAS를 지속적으로 재구축해야 합니다. 이러한 경우 비용이 더 많이 드는 BLAS 재구축을 수행하거나, 동일한 BVH 트리 구조를 재사용하는 비용이 덜 드는 BLAS 재적합(refit)을 수행할 수 있습니다. 후자의 경우 주의가 필요합니다. BLAS 구축 시 사용된 원본 위치에서 정점 위치가 너무 멀리 벗어나면 트리 품질이 재적합 횟수가 늘어날수록 악화될 수 있기 때문입니다. 이 경우 더 많은 탐색 단계가 필요해 해당 메시에 대한 레이 트레이싱 시간이 증가합니다. 이러한 상황에서는 N회 재적합 후 주기적으로 BLAS를 완전히 재구축하는 것이 도움이 될 수 있습니다. 실제 작업에서는 AS 빌드 시간, 트레이스 성능, 메모리 소비량 간에 상당히 많은 절충점을 고려할 수 있습니다.
향후 DXR 1.2 업데이트에서는 셰이더 실행 재정렬 기능이 추가될 예정입니다. 이 기능은 일부 GPU가 사용자가 제공한 정렬 키를 기반으로 웨이브를 재정렬하고 재패킹할 수 있게 합니다. 이를 통해 머티리얼 ID 등을 기준으로 웨이브를 재패킹함으로써 히트 셰이딩의 발산(divergence)을 줄일 수 있으며, 결과적으로 단일 셰이더 경로를 실행하는 더 완전한 웨이브를 얻을 수 있습니다.
DXR은 AMD RDNA2 이상, Nvidia Turing 이상, Intel Xe-HPG 이상에서 완전히 지원됩니다. Nvidia는 특정 Pascal GPU에서 더 제한적인 Tier 1도 지원하는데, 이는 RayQuery/인라인 추적은 지원하지 않고 DXR 1.0 스타일의 RayGen 추적만 지원합니다. 이 하드웨어는 실제로 레이 트레이싱을 위한 내장 하드웨어 가속 기능이 없으므로, 개인적으로는 유일한 선택지가 아닌 이상 신경 쓰지 않는 것이 좋습니다.
Mesh Shaders
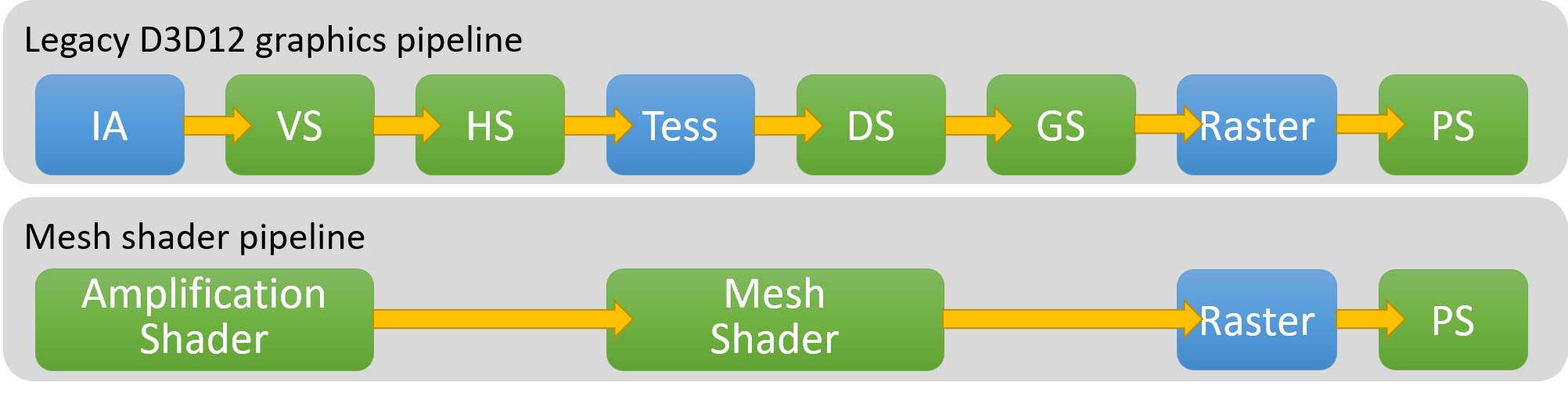
메쉬 셰이더 는 엔비디아의 튜링 아키텍처에서 처음 도입된 또 다른 잘 알려진 기능입니다. 메쉬 셰이더는 실제로 두 개의 별도 부분으로 구성됩니다: 메쉬 셰이더와 증폭 셰이더입니다. 후자는 선택 사항이므로 먼저 메쉬 셰이더에 대해 설명하겠습니다.
메쉬 셰이더를 사용할 때는 래스터화 전 정점 처리를 위해 기존의 정점 셰이더, 헐 셰이더, 도메인 셰이더, 지오메트리 셰이더 단계를 더 이상 사용하지 않습니다. 대신 메쉬 셰이더는 더 컴퓨트 중심의 설정을 제공하는데, 여기서 스레드 그룹이 정점과 로컬 인덱스의 배치를 생성하며 이들이 함께 삼각형 배치를 구성합니다. 주요 이점은 상당한 유연성입니다: 고정 기능 인덱스 버퍼나 고정 기능 버텍스 페치가 더 이상 존재하지 않으며, 삼각형 배치를 생성하는 방법은 전적으로 코드에 달려 있습니다. 그룹 공유 메모리를 활용할 수 있는 스레드 그룹을 사용하므로, 그룹 내 스레드 간 협업을 통해 출력 데이터를 생성할 수도 있습니다. 이를 통해 절차적 지오메트리 생성, 삼각형별 데이터 계산, 버텍스 데이터 압축 해제 등 흥미로운 가능성을 구현할 수 있습니다.
메쉬 셰이더가 주로 사용되는 방식은 클러스터라고도 불리는 메쉬릿을 위한 것입니다. 기본적으로 메쉬를 최대 N개의 정점과 M개의 삼각형(예: 64개 정점과 128개 삼각형)으로 구성된 덩어리로 분할한 후, 각 메쉬릿을 개별적으로 컬링하여 세밀한 컬링을 구현할 수 있습니다. 이는 메쉬 셰이더와 매우 잘 매핑됩니다. 각 메쉬릿마다 하나의 스레드 그룹을 할당할 수 있기 때문입니다. 메쉬 셰이더 내부에서는 양자화 및 정규화된 버텍스 데이터를 메쉬릿 경계에 따라 압축 해제하는 등의 작업을 수행할 수 있습니다. 원한다면 개별 삼각형 수준에서 컬링을 수행하고 컬링을 통과한 삼각형과 버텍스만 출력할 수도 있습니다. 그러나 메슬릿 생성 및 메쉬 셰이더 작성 시 주의가 필요합니다. 메쉬 셰이더를 사용하면 버텍스 셰이더 출력의 자동 "캐싱" 기능을 포기하게 되며, 메슬릿 간 "공유" 버텍스 수를 최소화하여 중복 버텍스 로드 및 변환을 줄이는 것은 개발자의 책임입니다. 또한 GPU마다 메쉬 셰이더의 정점/삼각형 출력 수 또는 개별 삼각형 컬링에 대한 성능 특성이 다릅니다.
증폭 셰이더는 메시 셰이더와 함께 제공되는 또 다른 구성 요소입니다. 앞서 언급했듯이 이는 선택 사항으로, 원한다면 메시 셰이더 그룹을 직접 호출할 수 있습니다. 증폭 셰이더가 있다면, 이는 메시 셰이더 단계 직전에 실행되는 추가 셰이더 단계입니다. 증폭 셰이더는 스레드 그룹으로 디스패치된다는 점에서 컴퓨트 셰이더와 유사하지만, DispatchMesh()를 통해 셰이더 내부에서 메쉬 셰이더 그룹을 디스패치할 수 있다는 특별한 기능을 가집니다. 이때 페이로드를 함께 전달하면, 메쉬 셰이더가 이를 활용하여 처리해야 할 메쉬릿(또는 유사한 객체)을 식별할 수 있습니다. 자연스러운 사용 사례는 증폭 셰이더 내에서 바로 컬링 및/또는 LOD 선택을 수행한 후, 컬링을 통과한 메시릿에 대해서만 메시 셰이더 그룹을 디스패치하는 것입니다. 별도의 컴퓨트 셰이더 디스패치, 출력 버퍼 또는 간접 인수를 설정할 필요가 없기 때문에 매우 편리합니다: 모든 작업이 그래픽스 파이프라인 내에서 바로 이루어집니다. 일부 하드웨어에서는 더 많은 데이터를 "온칩" 상태로 유지하는 측면에서도 이점이 있을 수 있습니다. 반면 다른 하드웨어에서는 컴퓨트 + 간접 디스패치 방식보다 덜 최적일 수 있습니다. 후자가 대형 GPU를 작업으로 완전히 채우는 데 더 효과적일 수 있기 때문입니다. 특히 AMD는 커닝을 지나치게 많이 수행하는 증폭 셰이더(또는 작업량이 적은 메시 셰이더)에 어려움을 겪을 수 있습니다. 명령 프로세서를 통해 링 버퍼를 사용하는데, 이 버퍼가 가득 차기 때문입니다.
Work Graphs

워크 그래프 는 D3D12에 추가된 비교적 새롭고 널리 알려진 기능입니다. 다소 복잡하지만, 아주 간략하게 설명해 보겠습니다. 간단히 말해, 작업 그래프는 GPU가 스스로 작업(work)을 공급받는 새로운 패러다임입니다. ExecuteIndirect에 의존하는 대신, 컴퓨트 노드들의 그래프를 구성할 수 있습니다. 여기서 한 노드는 연결된 다른 노드를 위해 스레드 그룹을 실행할 수 있습니다. 예를 들어, 픽셀 타일을 분류하는 노드가 있을 수 있으며, 그 분류 결과에 따라 N개의 특수화된 노드 중 하나를 선택합니다. 첫 번째 노드는 선택된 노드를 사용하여 스레드 그리드를 실행할 수 있으며, 이는 중간 단계 없이 실시간으로 적절한 셰이더를 선택하는 효과를 냅니다. 물론 몇 가지 제한 사항이 존재합니다… 특히 그래프 실행 전에 PSO를 구축할 때 그래프의 토폴로지가 정적으로 알려져 있어야 합니다. 또한 노드 그룹 간 재귀는 허용되지 않으며, 동일한 노드 내에서만 재귀할 수 있습니다. 하지만 간접 디스패치를 실행하는 기존 방식에 비해 여전히 상당히 유연하고 강력합니다.
워크 그래프는 상당히 새로운 기술이기 때문에 여전히 여러 가지 큰 의문점이 남아 있습니다. 특히 성능 측면에서 그렇습니다. 워크 그래프를 출시한 RDNA3 하드웨어에서는 간단한 그래프를 만드는 것이 확실히 쉬웠지만, ExecuteIndirect에 해당하는 명령어에 비해 성능이 현저히 떨어졌습니다. 그러나 AMD는 더 복잡한 반례 를 제시하기도 했는데, 여기서 그들은 ExecuteIndirect의 성능을 (소폭이지만) 능가하면서도 훨씬 적은 메모리를 사용했습니다. 성능 향상이 보장되지 않는 상황에서 워크 그래프가 GPU 기반 컴퓨팅 스케줄링의 미래 방식으로 진정으로 자리 잡을지 판단하기는 어렵습니다. 이 기술의 이점을 얻으려면 어느 정도 전폭적으로 도입해야 하는 측면이 있으며, 이러한 급진적인 변화가 그 이점을 정당화할 수 있을지는 아직 불분명합니다.
워크 그래프는 메쉬 노드에 대한 미리 보기 지원도 제공합니다. 메쉬 노드는 본질적으로 메쉬 셰이더 스레드 그룹에 불과합니다. 이는 워크 그래프에서 직접 삼각형을 생성하고 래스터화할 수 있음을 의미하며, 단일 대형 그래프 내에서 GPU 기반 메쉬 파이프라인 구축이 가능해질 수 있습니다. 이 메쉬 노드 기능은 작성 시점에는 아직 출시되지 않았으며, 1.715.0 이상 프리뷰 Agility SDK에서 사용할 수 있습니다.
현재 워크 그래프는 AMD의 경우 RDNA3 이상, Nvidia의 경우 Ampere 이상에서 지원됩니다. 인텔은 제품 라인 전반에 걸쳐 지원하지 않습니다.
New Shader Features
Wave Ops
웨이브 연산은 DXC/DXIL이 처음 출시되었을 때 추가된 HLSL의 강력하지만 사용하기 어려운 기능입니다. 이 내장 함수들은 "웨이브"(워프, 웨이브프론트 또는 서브그룹이라고도 함) 내 스레드 간 간단한 통신을 가능하게 하며, 그룹 공유 메모리나 전역 메모리를 통한 통신보다 훨씬 빠르고 간단할 수 있습니다. 이 중 가장 간단한 것은 브로드캐스트 연산으로, 한 스레드가 특정 인접 스레드의 변수 값을 볼 수 있게 합니다. 이를 수행할 수 있는 두 가지 내장 함수는 WaveReadLaneFirst 와 WaveReadLaneAt이며, 후자는 값이 브로드캐스트될 스레드/레인의 인덱스를 지정할 수 있게 합니다. 또 다른 일반적인 연산은 "볼로팅"(WaveActiveBallot) 연산으로, 전체 웨이브에 걸쳐 조건이 참인지 거짓인지 나타내는 비트 마스크를 제공합니다. 이를 활용하여 웨이브 내 모든 스레드에 대해 조건이 참인지, 아니면 웨이브 내 어느 스레드에 대해 참인지 판단하는 상위 수준 연산을 구축할 수 있습니다. 이 두 연산은 WaveActiveAllTrue 와 WaveActiveAnyTrue로 편리하게 노출되며, 분기점이 전혀 발생하지 않는 분기 구조를 설계하는 데 유용합니다. 마지막으로, 축소 및 스캔 내장 함수가 있습니다. WaveActiveSum과 같은 축소 함수는 웨이브의 모든 스레드에 대해 수학적 연산을 수행하고 그 결과를 반환합니다. 반면 스캔 내장 함수(예: WavePrefixCountBits)는 웨이브 전체에 걸쳐 선행 합계 또는 선행 곱셈을 수행하고 각 스레드에 해당 레인까지의 누적 결과를 남깁니다.
웨이브 연산은 스칼라화(scalarization)와 같은 여러 흥미로운 저수준 최적화의 일부입니다. 그러나 정의되지 않은 결과를 생성하지 않도록 상당한 주의를 기울여 사용해야 합니다. 웨이브 크기는 하드웨어 벤더마다, 심지어 동일한 하드웨어의 서로 다른 셰이더 간에도 차이가 있습니다. 테스트한 특정 웨이브 크기에서는 우연히 작동하지만 다른 크기에서는 심각하게 오류가 발생하는 웨이브 인식 코드를 작성하는 것은 매우 쉽습니다. 일반적으로 HLSL 언어는 스레드가 완전히 독립적이라는 개념을 중심으로 설계되었으며, 웨이브 연산은 그룹 공유 메모리와 유사한 방식으로 이러한 가정을 완전히 무너뜨립니다. 이는 특히 분기 및 비활성 레인과 관련하여 정의되지 않은 동작을 유발하기 매우 쉽습니다.
AMD 하드웨어는 베가(Vega)까지 Wave64만을 사용했으나, 모든 RDNA+ GPU는 Wave32와 Wave64를 모두 지원합니다. 엔비디아(Nvidia)는 전체 제품 라인에서 Wave32만을 독점적으로 지원합니다. 인텔(Intel)은 역사적으로 웨이브 크기가 상당히 달랐으며, 아키텍처에 따라 8, 16, 32 크기의 웨이브를 조합하여 사용해 왔습니다.
Quad Ops
쿼드 연산은 웨이브 연산과 매우 유사하지만, 래스터화 과정에서 2x2 쿼드를 형성하는 4개의 픽셀 셰이더 스레드에 대해 작동한다는 점이 다릅니다. 이러한 쿼드 연산 중 상당수는 이전 버전의 HLSL에서도 ddx_fine() 및 ddy_fine()을 교묘하게 활용하여 수행할 수 있었지만, 쿼드 연산은 작업을 훨씬 더 단순화합니다. 특히, 입력 커버리지 마스크와 결합된 몇 가지 쿼드 연산을 사용하여 쿼드 오버셰이딩 시각화 도구 를 매우 쉽게 구현할 수 있습니다.
16-bit floats and integers
DXC와 셰이더 모델 6.2는 HLSL에 저정밀도 타입과 수학 연산을 (재)도입했습니다. 특히 16비트 부동소수점, 정수, 부호 없는 정수 타입이 포함됩니다. 무엇보다도 이 타입들은 수동 변환 및 비트 패킹 코드를 작성하지 않고도 데이터를 버퍼에 더 촘촘하게 패킹하는 데 탁월합니다. 하지만 신중하게 사용한다면 셰이더의 ALU 처리량 향상 및/또는 레지스터 사용량 감소를 기대할 수 있습니다. 다만 기존 코드를 개조할 때 실제로 구현하기는 상당히 까다롭습니다. fp16과 fp32 사이의 숨겨진 암시적 변환을 실수로 도입하기 매우 쉽기 때문입니다. 또한 일부 하드웨어(특히 AMD)는 두 개의 독립적인 입력/출력 세트에 동일한 fp16 연산을 수행하는 "패킹된" 명령어를 통해서만 더 높은 연산 처리량을 달성할 수 있습니다.
16비트 형식은 AMD Vega 이상, Nvidia Turing 이상, 그리고 모든 DX12 지원 Intel GPU에서 지원됩니다.
Barycentrics
중심점은 기본적으로 삼각형 표면의 좌표로, 삼각형의 세 꼭짓점에서 정점별 속성을 보간하는 데 사용됩니다. 대부분의 현대 하드웨어는 픽셀 셰이더 시작 부분에서 어느 정도 소프트웨어를 통해 이 보간을 수행하므로, 셰이더 작성자에게 이 목적을 위해 사용되는 중심점을 노출할 수 있습니다. 이를 통해 원하는 경우 자체 보간 알고리즘을 구현할 수 있으며, 자동 보간 시보다 속성을 더 압축적이고 간결하게 패킹할 가능성이 있습니다. 또한 추가 패스(또는 지오메트리 셰이더!) 없이도 픽셀 셰이더 내에서 직접 앤티앨리어싱 처리된 와이어프레임 렌더링 같은 멋진 작업을 수행할 수 있습니다.
중심점 계산은 AMD RDNA 2 이상, Nvidia Turing 이상, Intel Xe2 이상에서 지원됩니다.
Shader Libraries & Linking
셰이더 라이브러리 컴파일을 위한 HLSL lib_6_x 프로파일은 원래 레이 트레이싱 상태 객체와 함께 사용하기 위해 Shader Model 6.3의 일부로 추가되었습니다. 잘 알려지지 않은 기능이지만, 표준 그래픽 및 컴퓨트 셰이더의 일반적인 오프라인 셰이더 링크 에도 사용할 수 있습니다. 기본적으로 먼저 적절한 셰이더 스테이지 속성으로 엔트리 포인트를 태그하여 라이브러리를 컴파일한 다음, DXC를 사용하여 엔트리 포인트를 라이브러리에 정의된 함수와 링크할 수 있습니다. DXC는 링크 경계를 넘어 최적화를 수행하는 것으로 보입니다. 따라서 이론상으로는 링크 없이 컴파일하는 경우보다 DXIL 코드 생성이 열악해지지 않아야 합니다. 이는 컴파일 시간 단축을 위한 유용한 옵션이 될 수 있습니다.
Helper Lane Detection And Control
헬퍼 레인은 픽셀 셰이더가 실행되는 2x2 쿼드에서 누락된 항목을 "채우기" 위해 생성되는 특수한 픽셀 셰이더 스레드입니다. 이 레인은 어떤 종류의 출력도 생성하지 않지만, 쿼드 전체에 걸쳐 차분 연산을 수행할 때 미분 연산이 올바르게 작동하도록 인접 레인과 함께 일반적인 계산을 수행합니다. 이러한 레인을 생성하는 표준 방식은 삼각형 모서리에서 이루어집니다: 쿼드 내 모든 픽셀 셰이더 스레드는 동일한 삼각형에 속해야 하므로, 부분적으로 덮인 쿼드에는 쿼드를 채우기 위해 헬퍼 레인이 생성됩니다(해당 픽셀이 어떤 삼각형에도 덮이지 않더라도). 그러나 픽셀 셰이더 실행 중 동적으로 발생할 수도 있습니다. 특히 discard 명령은 픽셀 셰이더 스레드를 헬퍼로 "강등"시켜, 웨이브 내 남아 있는 "활성" 스레드들이 평소처럼 미분 계산과 텍스처 샘플링을 계속할 수 있게 합니다. 두 경우 모두, IsHelperLane() 내장 함수를 사용하여 이러한 스레드를 식별하고, 해당 스레드가 존재할 때 특별한 경우의 로직을 수행할 수 있습니다.
Dynamic Resources (ResourceDescriptorHeap)
D3D12의 첫 번째 릴리스는 바인들리스 리소스를 지원했지만, HLSL에서 경계 없는 리소스 배열을 다소 투박하게 사용하고 루트 시그니처에 대한 반복적인 코드를 결합해야 했습니다. 게다가 루트 시그니처를 변경할 때마다 "하나의 큰 디스크립터 테이블"을 각 명령어 목록의 루트 시그니처에 바인딩해야 했습니다. 셰이더 모델 6.6과 동적 리소스는 이러한 모든 문제를 해결합니다. 대신 어디서든 접근 가능한 마법 같은 ResourceDescriptorHeap 배열을 얻게 되며, 이 배열은 바인딩된 디스크립터 힙의 지정된 인덱스에 존재하는 리소스를 제공합니다. 이를 통해 원한다면 루트 시그니처에서 거의 모든 것을 제거하고, 대신 셰이더가 필요한 디스크립터 인덱스를 가져오는 데 사용할 수 있는 몇 가지 루트 상수나 루트 CBV/SRV만 제공하면 됩니다. 바인들리스에 기술적으로 필수적인 것은 아니지만, 훨씬 더 간단하고 깔끔해집니다. 이는 특히 StructuredBuffer에 해당됩니다. 기존 방식에서는 요소에 사용한 모든 가능한 구조체 유형에 대해 별도의 무제한 리소스 배열을 선언해야 했습니다.
리소스 디스크립터 힙과 함께, 샘플러 디스크립터 힙도 존재합니다. 샘플러 디스크립터 힙을 제외하면 완전히 동일하게 작동합니다. 이로 인해 바인들리스 샘플러가 필요한 경우, 이를 동일하게 간단하게 구현할 수 있습니다.
WaveSize
앞서 언급했듯이, 웨이브 연산은 모든 가능한 웨이브 크기에서 효과적으로 작동하도록 사용하는 것이 정말 어렵습니다. 특히 컴파일 시점에 웨이브 크기가 알려지지 않기 때문에, 별도의 웨이브 크기에 대한 로직은 반드시 WaveGetLaneCount()에 대한 조건문으로 표현되어야 합니다. Shader Model 6.6의 [WaveSize(N)] 내장 함수는 컴퓨트 셰이더가 지정된 웨이브 크기에서만 작동할 수 있도록 지정할 수 있게 함으로써 이러한 문제를 해결하고자 합니다. 이는 런타임에 강제 적용되며, 현재 장치 및 드라이버가 해당 웨이브 크기를 지원하지 않을 경우 PSO 생성이 실패합니다. 이 기능이 도움이 되기는 하지만, 지원하고자 하는 모든 가능한 웨이브 크기에 대해 동일한 셰이더를 N번 컴파일해야 한다는 점에서 여전히 까다로운 상황입니다. 또한 D3D가 허용하는 모든 가능한 웨이브 크기를 지원하지 않을 경우 웨이브 연산을 사용하지 않는 일종의 대체 방안을 마련하고 싶을 것입니다.
Derivatives In Compute
전통적으로 쿼드는 픽셀 셰이더에서만 존재하는 개념이었으며, 이는 픽셀 셰이더가 파생 내장 함수나 암시적 LOD 밉 레벨 선택이 가능한 텍스처 샘플링 함수를 사용할 수 있는 유일한 단계임을 의미했습니다. 이 셰이더 모델 6.6 기능은 스레드 그룹 내 특정 스레드가 쿼드 인덱스에 매핑되는 방식에 관한 규칙을 지정함으로써 컴퓨트 셰이더에도 쿼드를 도입합니다. 셰이더를 작성할 때 이러한 규칙을 신중하게 준수하면, 그라디언트를 전달하거나 직접 밉 레벨을 계산할 필요 없이 일반적인 Texture2D.Sample 함수를 사용하여 밉 선택을 얻을 수 있습니다. 이 사양은 스레드 그룹 내에서 스레드가 웨이브에 매핑되는 방식을 완전히 명시하지 않으므로, 컴퓨트에서 웨이브 배열에 대한 가정하지 않도록 주의해야 합니다.
64-Bit Atomics and Atomic CAS For Floats
이 기능 이전에는 원자 연산이 32비트 정수에서만 수행될 수 있었습니다. 셰이더 모델 6.6은 이를 변경하여 이제 버퍼와 텍스처에서 64비트 정수에 대한 원자 연산을 수행할 수 있게 합니다. 이는 소프트웨어 래스터라이징을 통해 가시성 버퍼로 처리하는 나나이트 방식을 채택할 경우 확실히 유용합니다. 또한 SM 6.6은 fp32 값에 대한 원자 연산을 매우 제한적으로 지원합니다. 특히 InterlockedCompareStoreFloatBitwise 와 InterlockedCompareExchangeFloatBitwise를 도입했습니다. 이 명령어들은 기본적으로 부동소수점 비트를 uint32_t로 처리하여 일반적인 원자적 CAS(비교 교환)를 수행합니다.
Raw Texture Gather
원시 텍스처 개더는 특정 정수 텍스처 형식에서 4텍셀 개더를 수행할 수 있게 해주는 흥미로운 셰이더 모델 6.7 기능입니다. R16_UINT, R32_UINT 또는 R32G32_UINT 형식의 텍스처를 사용할 경우, 2x2 크기의 텍셀 쿼드를 수집하여 필터링되지 않은 원시 바이트 형태로 셰이더에 반환할 수 있습니다. 이는 정수 텍스처 형식에서 Gather 사용에 대한 기존 제한을 우회합니다.
Writable MSAA Textures
이름에서 알 수 있듯이, 이 셰이더 모델 6.7 기능은 셰이더가 새로운 RWTexture2DMS 및 RWTexture2DMSArray HLSL 리소스 유형을 통해 MSAA 텍스처에 직접 쓰기를 가능하게 합니다. 이전에는 렌더 타깃 뷰를 통해서만 쓰기가 가능했거나, 복사/해결 작업을 통해서만 가능했습니다.
SampleCmpLevel
SampleCmpLevel 은 SampleCmpLevelZero와 유사하지만, 0번째 밉 레벨만 샘플링할 수 있는 대신 특정 밉 레벨을 전달할 수 있다는 점이 다릅니다.
ByteAddressBuffer Types Load and Store
이것은 셰이더 모델 기능이 아니라 DXC가 이제 언어 수준에서 지원하는 기능입니다. uint/2/3/4 를 ByteAddressBuffer에서 uint/2/3/4 만 로드할 수 있었던 것과는 달리, 이제 템플릿화된 Load<T> 메서드를 통해 오프셋 위치에서 임의의 타입이나 구조체를 로드할 수 있습니다(4바이트 정렬 기준, 16비트 타입 지원 시 2바이트 정렬). 또한 동일한 방식으로 작동하는 Store<T> 함수가 RWByteAddressBuffer 에 추가되었습니다. 이러한 새로운 메서드와 함께 DXC는 sizeof() 지원도 추가했습니다. 이를 통해 StructuredBuffer와 유사하게 임의의 유형 배열에서 로드할 수 있습니다:
MyStruct s = byteAddressBuffer.Load<MyStruct>(index * sizeof(MyStruct));
SV_StartVertexLocation + SV_StartInstanceLocation
많은 사람들이 BaseVertexLocation 및 StartInstanceLocation 매개변수가 DrawIndexedInstanced 의 SV_VertexID 및 SV_InstanceID 시스템 값 입력값에 영향을 미치지 않는다는 사실을 알게 되면 당황합니다. 대신, 입력 어셈블러에서 발생하는 고정 함수 버텍스 페치에만 영향을 미칩니다. GL과 Vulkan은 이런 식으로 작동하지 않고 버텍스 셰이더에 버텍스 및 인스턴스 오프셋을 제공하는 메커니즘을 가지고 있기 때문에 이는 특히 혼란스럽습니다. 이 새로운 기능은 SV_StartVertexLocation 및 SV_StartInstanceLocation 시스템 값 입력을 제공하여 BaseVertexLocation 및 StartInstanceLocation 매개변수의 값을 포함하는 새로운 SV_StartVertexLocation 및 SV_StartInstanceLocation 시스템 값 입력을 제공합니다. 이는 ExecuteIndirect를 사용하는 GPU 기반 렌더링 파이프라인에서 특히 유용할 수 있는데, 결과적인 드로우에 데이터를 전달하는 추가적인 방법을 제공하기 때문입니다.
Enums
이상하게도 HLSL은 DXC가 HLSL 2017 지원을 추가하기 전까지 C 스타일 열거형을 지원하지 않았습니다. 이제 C++에서와 마찬가지로 일반적인 열거형 및 열거형 클래스 선언을 할 수 있습니다.
Templates
HLSL 2021은 HLSL에 템플릿 유형 및 함수에 대한 제한적 지원을 추가했습니다. 이는 언어 작성 방식에 긍정적·부정적 측면 모두에서 막대한 영향을 미치는 중대한 변화임이 분명합니다. 그러나 이 기능은 의심할 여지 없이 강력하고 유연하여, 이전에는 매크로나 코드 중복이 필요했던 많은 곳에서 순수 템플릿 기반 HLSL 코드를 사용할 수 있게 합니다. 예를 들어, 바인들리스 리소스 디스크립터 주변의 래퍼를 만들거나, 과감하게 템플릿화된 구면 조화 함수 수학 라이브러리를 구현할 수도 있습니다. 다만 컴파일 시간과 이해하기 어려운 컴파일 오류에 주의해야 합니다.
Operator Overloading
템플릿과 함께 HLSL 2021은 사용자 정의 유형에 대해 제한된 연산자 하위 집합의 중복 정의를 허용합니다. 일반적인 산술 연산자, 비트 연산자, 비교 연산자, 함수 연산자 및 배열 인덱스 연산자가 모두 지원됩니다. 주요 예외는 * 및 &와 같은 포인터 관련 연산자와, +=와 같이 this에 대한 참조를 반환해야 하는 연산자들입니다.
Bitfields
비트필드는 제한된 비트 수에 많은 데이터를 촘촘히 압축하는 데 유용하며, 이는 GPU에서 자주 수행하는 작업입니다. 비트필드 지원으로 인해 16비트 미만의 공간에 값을 저장하기 위해 수동으로 마스크 처리나 비트 시프트를 작성할 필요가 없어집니다.
C++-Style Function Overloading and For Loop Scoping
HLSL의 이상한 특징 중 하나는 기이한 중복 정의 해결 방식이었습니다. C++처럼 순전히 인자의 개수와 유형에 기반해 중복 정의를 하는 대신, 사용자 정의 타입을 기본 구성 요소로 '분해'한 후 이를 기준으로 중복 정의를 수행했습니다. 이는 최소한으로 말해도 매우 놀라운 일이었습니다. HLSL 2021은 이 문제를 해결하고 여러분이 익숙할 일반적인 중복 정의 규칙을 사용합니다.
HLSL 2021에서 해결된 또 다른 특이한 문제는 for 블록 내에서 선언된 모든 요소에 대한 루프 범위 지정이었다. 2021 이전에는 for 내부의 모든 요소가 루프의 상위 범위에서 유지되었다. 이는 다음과 같은 코드에서 for (uint i = 0; i < length; ++i) { } i 변수가 루프 종료 후에도 지속된다는 것을 의미했습니다. HLSL 2021에서는 i 는 루프 본문에서만 존재하게 되며, 이는 C++ 및 C99에서 처리하는 방식과 동일합니다.
Developer Workflow Enhancements
Agility SDK + Independent Devices
지금까지 읽어오신 분이라면 이미 짐작하셨겠지만, D3D12는 처음 출시된 이후 엄청나게 많이 바뀌었습니다. 하지만 초기에는 주요 Windows 10 업데이트에 연계되어야 했기 때문에 이러한 변경 사항이 적용되는 속도가 상당히 느릴 수밖에 없었습니다. 끊임없이 진화하는 API에겐 좋지 않은 일이며, 잠재적 사용자 기반 전체에 걸쳐 최소한의 사용 가능한 기능 세트를 보장해야 하는 개발자들에게는 정말 좋지 않은 일입니다. Agility SDK 는 주요 DX12 릴리스 및 추가 기능을 OS 릴리스 주기와 분리하고, 대신 최종 사용자에게 배포할 수 있는 D3D12Core.dll로 묶어 이 두 가지 문제를 해결하고자 했습니다. 작동 방식은 다소 흥미롭습니다: 앱이 자체 배포된 D3D12Core.dll만 사용하는 대신, D3D 로더는 설치된 OS 버전의 D3D12Core.dll도 확인하여 더 최신 버전을 사용합니다. 이렇게 하면 앱은 버그 수정 및 업데이트를 계속 받을 수 있으면서도 사용 가능한 기능의 최소 기준을 보장할 수 있습니다.
Agility SDK 개발자 스토리는 원래 다소 복잡했습니다. D3D12Core.dll, 디버그 레이어 DLL, 그리고 해당 d3d12.h 헤더를 얻는 건 충분히 쉬웠습니다. Windows SDK의 d3d12.h 대신 최신 버전을 포함하도록 포함 경로를 주의 깊게 설정해야 했지만, 그건 그리 어렵지 않았습니다. 하지만 진짜 성가신 부분은 D3D 로더가 Agility SDK 사용을 인식하도록 하는 "마법 같은" 수출 항목을 실행 파일에 설정하는 것이었습니다. 여기에는 D3D12Core.dll의 상대 경로를 포함한 문자열과 의도한 Agility SDK 버전을 나타내는 정수를 수출해야 했습니다. 이것은 패키징과 개발 빌드 모두에 약간 성가신 일이었습니다... 여러 가지 이유로 D3D12Core.dll을 실행 파일과 같은 폴더에 두고 싶지 않았기 때문에, 실행 파일에 상대적인 알려진 하위 폴더에 배치해야 했습니다. 그러나 진짜 문제는 D3D12 디바이스를 사용하려는 앱 플러그인에서 발생했습니다. "매직" 수출 항목이 실행 파일에 있어야 하므로 플러그인이 원하는 Agility SDK를 지정할 방법이 없었습니다. 따라서 기본 앱이 지정한 SDK(아마도 Agility SDK가 전혀 없을 가능성이 높음)를 그대로 사용해야만 했습니다. 독립 장치 기능은 Agility SDK 세부 사항을 지정할 수 있는 API를 제공함으로써 이 두 가지 문제를 모두 해결합니다. 이를 위해 D3D12는 기존에 사용하던 "프로세스당 하나의 장치" 규칙을 변경해야 했으며, 이 때문에 이 기능이 "독립 장치"로 명명되었습니다.
Debug Layer Callback
디버그 레이어는 프로그래머의 실수나 정의되지 않은 동작이 발생하기 전에 잡아내는 데 매우 가치 있고 유용합니다. 또한 오류 발생 시 디버거로 중단하도록 레이어에 지시할 수 있는 편리한 기능을 제공하여, 실제로 오류를 발생시킨 코드 줄을 포착하는 데 더욱 유용합니다. 그러나 오류 메시지 자체는 항상 디버거 출력 스트림으로 출력되었는데, 이는 Visual Studio에서는 표시되지만 그 외에는 직접 해석하기가 매우 어렵습니다. 이는 특히 Vulkan에서 온 개발자에게 더욱 답답할 수 있습니다. Vulkan의 검증 레이어는 오류가 발생하자마자 그 세부 정보를 전달받는 콜백을 설치할 수 있게 해주기 때문입니다. D3D12는 마침내 Windows 11 출시와 함께 이를 따라잡았습니다. Windows 11은 디버그 레이어가 메시지를 생성할 때마다 호출되는 콜백을 설치할 수 있는 새로운 API를 추가했습니다. 이제 원하는 방식으로 어설션, 출력, 로깅 등을 수행할 수 있습니다.
Device Removed Extended Data (DRED)
PC에서 GPU 충돌을 디버깅하고 해결하는 과정은 전반적으로 매우 불만족스럽습니다. 문제가 발생하면 여러 추상화 계층과 블랙박스의 반대편에 위치하게 되어 근본 원인을 찾기가 극히 어렵습니다. DRED는 GPU가 충돌할 당시 수행 중이던 작업(정확히는 이미 완료된 작업)에 대한 정보를 제공함으로써 이 거의 불가능한 작업을 조금이나마 돕고자 합니다. 기본적으로 DRED는 WriteBufferImmediate 를 사용하여 명령 목록에 기록된 다양한 명령(예: PIX 마커나 드로우 콜)에 대한 "브레드크럼"을 자동 생성합니다. 그런 다음 장치가 제거되면 DRED API를 사용하여 각 명령 버퍼의 상태를 덤프하고 GPU가 도달한 브레드크럼 표시기를 확인할 수 있습니다. 운이 좋다면 이 정보가 충돌을 일으킨 특정 패스나 디스패치를 가리킬 수 있습니다. 페이지 오류의 경우 DRED는 페이지 오류 주소에 해당하는 리소스 디버그 이름 목록도 제공할 수 있습니다... 비록 실제로는 알 수 없는 이유로 이 정보가 종종 누락되는 경우가 많다는 점을 발견했습니다.
What’s Changed For Me Personally
All-In On Bindless and “User-Space Bindings”
Bindless는 처음에는 재미있는 파티 트릭처럼 보일 수도 있고, 셰이더가 사용할 리소스를 스스로 결정해야 하는 상황에서만 사용하는 것처럼 보일 수 있습니다. 하지만 한번 완전히 도입하면 코드베이스와 작업 방식에 혁신적인 변화를 가져올 수 있습니다. 셰이더가 필요로 하는 텍스처와 버퍼를 사전에 정확히 알고 있는 경우에도, 제 경험상 기존 슬롯 기반 API를 사용하거나 디스크립터 테이블을 복잡하게 조립하는 것보다 바인들리스 방식을 통해 처리하는 것이 훨씬 더 나은 경험입니다. 이는 ResourceDescriptorHeap을 사용하는 SM 6.6 유형의 바인들리스에서 특히 그렇습니다. 기본적으로 접근할 수 있는 모든 리소스 디스크립터는 원하는 곳에 배치할 수 있는 간단한 uint32_t로 변환됩니다. 이 uint32_t 는 더 이상 불투명하지 않으며, 디스크립터 힙이나 디스크립터 세트, 또는 실제로 메모리를 소유하지 않는 다른 장소에 존재할 필요가 없기 때문에, 저는 이것을 "사용자 공간 바인딩"이라고 부르고 싶습니다. 구조체, 배열, 텍스처 등 원하는 모든 곳에 넣을 수 있습니다.
호스트 측에서는 단순화 가능성이 매우 큽니다. 특히 루트 시그니처는 거의 완전히 배제될 수 있으며, 모든 작업에 사용되는 소수의 글로벌 루트 시그니처나 심지어 단 하나의 시그니처만으로도 충분히 가능합니다. 루트 시그니처에서 신경 써야 할 것은 초기 "루트" 데이터를 셰이더에 전달하는 방식뿐입니다. 이는 루트 상수, 루트 CBV(콘트롤 블록 변수), 또는 루트 SRV(스트림 변수)일 수 있습니다. 이것이 마련되면, 다른 모든 리소스는 디스크립터 인덱스를 불러오는 방식으로 접근할 수 있습니다. 바인들리스가 아닌 설정에서는, "최적의" 루트 시그니처를 생성하기 위해 셰이더를 리플렉팅하거나, 테이블 바인딩 변경 빈도에 따라 분류된 디스크립터 테이블에 다양한 리소스를 구성하는 여러 경우를 처리하기 위해 수많은 루트 시그니처를 생성하는 등의 작업을 해야 할 수 있습니다. 바인들리스를 사용하면, 이 모든 것이 사라집니다! 루트 시그니처는 D3D12 장치 부팅을 처리하는 코드베이스의 한 구석에 넣어두고, 다시는 신경 쓸 필요가 없을 수 있습니다. 제 개인 코드베이스에서 사용하는 "범용" 루트 시그니처는 다음과 같으며, 시작 시 생성합니다:
D3D12_ROOT_PARAMETER1 rootParameters[NumUniversalRootSignatureParams] = {};
// Constant buffers
for(uint32 i = 0; i < NumUniversalRootSignatureConstantBuffers; ++i)
{
rootParameters[URS_ConstantBuffers + i].ParameterType = D3D12_ROOT_PARAMETER_TYPE_CBV;
rootParameters[URS_ConstantBuffers + i].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
rootParameters[URS_ConstantBuffers + i].Descriptor.RegisterSpace = 0;
rootParameters[URS_ConstantBuffers + i].Descriptor.ShaderRegister = i;
rootParameters[URS_ConstantBuffers + i].Descriptor.Flags = D3D12_ROOT_DESCRIPTOR_FLAG_DATA_STATIC;
}
// AppSettings
rootParameters[URS_AppSettings].ParameterType = D3D12_ROOT_PARAMETER_TYPE_CBV;
rootParameters[URS_AppSettings].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
rootParameters[URS_AppSettings].Descriptor.RegisterSpace = 0;
rootParameters[URS_AppSettings].Descriptor.ShaderRegister = AppSettings::CBufferRegister;
rootParameters[URS_AppSettings].Descriptor.Flags = D3D12_ROOT_DESCRIPTOR_FLAG_DATA_STATIC;
// Static samplers
D3D12_STATIC_SAMPLER_DESC staticSamplers[uint64(SamplerState::NumValues)] = {};
for(uint32 i = 0; i < uint32(SamplerState::NumValues); ++i)
staticSamplers[i] = GetStaticSamplerState(SamplerState(i), i, 0, D3D12_SHADER_VISIBILITY_ALL);
D3D12_ROOT_SIGNATURE_DESC1 rootSignatureDesc = {};
rootSignatureDesc.NumParameters = ArraySize_(rootParameters);
rootSignatureDesc.pParameters = rootParameters;
rootSignatureDesc.NumStaticSamplers = ArraySize_(staticSamplers);
rootSignatureDesc.pStaticSamplers = staticSamplers;
rootSignatureDesc.Flags = D3D12_ROOT_SIGNATURE_FLAG_CBV_SRV_UAV_HEAP_DIRECTLY_INDEXED;
DX12::CreateRootSignature(&UniversalRootSignature, rootSignatureDesc);
"바인드풀" 엔진은 디스크립터 테이블의 수명을 세심하게 관리하는 코드를 가질 수 있습니다. 테이블을 재사용할 수 있는지, 아니면 새 테이블을 생성해야 하는지 판단하기 위해 해시나 유사한 방법을 사용할 수도 있죠. 또한 텍스처 스트리밍이나 CPU 업데이트 버퍼를 위한 훅을 통해 SRV 디스크립터가 변경되었을 때 디스크립터 세트를 무효화해야 할 시점을 알 수 있을 것입니다. 다시 한번, 모두 사라졌습니다! 펑! 더블 버퍼링된 디스크립터 힙을 유지하고 GPU가 아직 접근 중인 디스크립터를 업데이트하지 않도록 해야 하는 건 여전히 필요하지만, 이는 간단하며 업데이트 대기열을 통해 중앙 집중식으로 관리할 수 있을 겁니다. 제 개인 코드베이스에서 리소스와 상수를 바인딩하는 방식은 다음과 같습니다:
MeshConstants meshConstants =
{
.World = world,
.View = camera.ViewMatrix(),
.WorldViewProjection = world * camera.ViewProjectionMatrix(),
.CameraPos = camera.Position(),
.Time = data.ElapsedTime,
.VertexBuffer = model->VertexBuffer().SRV,
.MeshletBuffer = model->MeshletBuffer().SRV,
.MeshletBoundsBuffer = model->MeshletBoundsBuffer().SRV,
.MeshletVerticesBuffer = model->MeshletVerticesBuffer().SRV,
.MeshletTrianglesBuffer = model->MeshletTrianglesBuffer().SRV,
};
camera.GetFrustumPlanes(meshConstants.FrustumPlanes);
DX12::BindTempConstantBuffer(cmdList, meshConstants, URS_ConstantBuffers + 0, CmdListMode::Graphics);
아주 간단합니다: 여러 상수들과 SRV 디스크립터 인덱스를 함께 가진 구조체를 초기화합니다. 이 구조체들은 따로 분리할 필요 없이 나란히 존재할 수 있습니다. 그런 다음 BindTempConstantBuffer 에서 프레임 수명 동안 CPU로 쓰기 가능한 임시 버퍼 메모리를 확보하고, 구조체 내용을 복사한 후 루트 시그니처에 루트 CBV로 한 번에 바인딩합니다. 원한다면 더 많은 디스크립터 인덱스를 가진 중첩 구조체를 간단히 만들 수도 있고, 즉석에서 생성하는 대신 지속적 버퍼에 이를 저장할 수도 있습니다. 어느 쪽이든 모두 제가 원하는 대로 제어하고 처리할 수 있어 매우 자유롭습니다.
셰이더 측면에서는 변혁적이지 않을 수 있지만, 바인들리스는 여전히 훌륭합니다. 초반에 약간의 마찰을 일으킬 수 있는 한 가지 측면은 HLSL에서 리소스를 전역 변수로 바로 사용할 수 없다는 점입니다. 대신 ResourceDescriptorHeap 를 명시적으로 사용해 리소스를 가져온 후 원하는 작업을 수행해야 합니다. 하지만 장기적으로 보면 리소스를 전역 변수로 강제하던 방식에 비해 매우 긍정적인 변화이며, 익숙해지면 코드를 훨씬 깔끔하고 조합 가능하게 만들 수 있습니다. 정말 원한다면 HLSL 리소스를 정적 전역 변수에 로드하여 기존 방식을 모방할 수도 있지만, 대규모 기존 코드베이스를 수정하는 경우가 아니라면 특별히 권장하지 않습니다. 물론 바인들리스를 사용하면 셰이더 내에서 자체 데이터 구조를 탐색하거나 머티리얼 ID를 기반으로 임의의 머티리얼 텍스처를 샘플링하는 등 매우 정교한 작업을 수행할 수도 있습니다.
특히 레이 트레이싱에서 바인들리스는 생명줄과도 같으며, 로컬 루트 시그니처와 셰이더 바인딩 테이블을 다루는 복잡한 작업을 크게 단순화해 줍니다. 사실 저는 Ray Tracing Gems II에서 이 주제에 대해 한 장 전체를 할애해 설명했습니다!
"바인들리스 에브리웨어"의 주요 단점은 주로 툴링과 내부 상태 분석에 있습니다. 바인딩이 드로우/디스패치 시점에 정적으로 알려진 경우, RenderDoc이나 PIX 같은 툴이 해당 바인딩을 가로채서 캡처 화면을 볼 때 나중에 표시해 주는 것은 매우 간단합니다. 비슷한 맥락에서, 검증 레이어 역시 특정 작업이 어떤 리소스에 접근했는지 알아야 하기 때문에 구식 바인딩 방식에서는 훨씬 수월하게 작동합니다. 바인들리스 방식에서는 셰이더를 실행하지 않고는 실제로 어떤 리소스가 접근되었는지 알 방법이 없습니다. 정확히 말하면, 정확한 정보를 원한다면 이러한 도구들이 이제 셰이더 바이트코드를 패치하여 인스펙션 데이터를 버퍼에 저장할 수 있는 새로운 명령어를 삽입한 후, 드로우나 디스패치를 실행한 뒤 해당 데이터를 수집하여 어떤 리소스가 접근되었는지 파악해야 합니다. 이 방법은 실제로 작동하지만, 이전에는 존재하지 않았던 상당한 복잡성을 도구 측면에 추가합니다. 비슷한 맥락에서 셰이더 리플렉션 API 역시 셰이더가 사용하는 리소스를 파악하는 데 거의 무용지물이 될 수 있으므로, 해당 정보에 의존하고 있다면 새로운 접근 방식이 필요할 수 있습니다.
HLSL Templates
템플릿은 항상 내게 복잡한 감정을 불러일으킨다. 유용하고 강력하다는 점은 부인할 수 없지만, 동시에 끝없는 문제점을 안고 있다. 부풀어 오른 컴파일 시간, 해독 불가능한 오류 메시지, 프로그래머들이 농사를 짓고 싶게 만드는 미친 SFINAE 곡예까지: 잠재적 단점은 무수히 많고 잘 알려져 있다. 하지만 다시 말해, 부인할 수 없이 유용합니다. 제 셰이더 코드에 신중하게 템플릿을 도입한 경험으로 볼 때, 템플릿을 추가한 것은 올바른 결정이었으며 없는 것보다 있는 편이 낫다고 생각합니다. 다만 C++ 코드에 접근할 때만큼이나 템플릿 사용에도 최소한 같은 수준의 주의를 기울이려 합니다. 즉, 복사/붙여넣기 코드가 조금 늘어난다 해도 가능한 한 더 단순하고 기술적으로 덜 복잡한 해결책을 우선적으로 선택한다는 의미입니다.
그럼 내가 그걸로 뭘 했을까? 목록은 꽤 길지만, 주요 내용은 다음과 같습니다:
- 이들은 fp32와 fp16 데이터 유형 모두에서 사용할 수 있도록 원하는 함수에 즉시 유용합니다. 함수를 중복 작성할 필요 없이 한 번만 작성하면 됩니다. 함수를 벡터 크기에 무관하게 만들 수도 있지만, 이는 다소 번거롭습니다. 이 두 가지의 예시를 보려면 저의 SHforHLSL 라이브러리 를 살펴보세요. 저차 구면 조화 함수 작업을 위한 타입과 함수를 구현한 라이브러리입니다. 사실 이 라이브러리는 템플릿 사용이 '지나치게 과도한' 지점을 파악해보는 좋은 사례이기도 합니다. 특히 단색과 RGB 변형에 대한 템플릿 처리가 코드 가독성을 저해하는 부분이 있다고 생각합니다. 코드를 직접 수정하지 않는 라이브러리에서는 괜찮을 수 있지만, 활발히 개발 중인 코드에서는 아마도 불편함을 느낄 것입니다. 템플릿이 적용되지 않은 Lite 버전과 비교해 보면, 템플릿이 없는 코드가 훨씬 깔끔해 보일 수 있습니다.
- 마찬가지로, 텍스처 유형에 대한 템플릿화는 코드가 float/float2/float3/float4 유형을 쉽게 처리할 수 있는 필터링 함수 같은 것을 구현하는 데 유용할 수 있습니다.
- 제가 작업한 일부 코드에서는 템플릿화된 "writer" 타입을 사용하는 알고리즘을 만들게 되었습니다. 이를 통해 동일한 코드를 사용하면서 출력을 버퍼에 기록하거나, 셰이더 printf를 사용해 결과를 로깅할 수 있게 되었습니다.
- 셰이더 printf에 관해 말하자면… 제 구현 은 형식 문자열을 처리하고 디버그 버퍼에 인수를 패킹하는 데 템플릿을 사용합니다.
- 실제로 사용해본 적은 없지만, Vulkan에서 제공하는 버퍼 장치 주소 기능을 에뮬레이트할 수 있는 버퍼 래퍼의 개념 증명 을 스케치해본 적은 있습니다. 실제 언어 지원에 비하면 상당히 투박하지만, 그래도 구현 가능하다는 점이 좋습니다.
C++과 마찬가지로 템플릿은 잠재적으로 문제가 될 수 있으며, 지나치게 사용하기 쉽다고 생각합니다. 하지만 동시에 신중하게 사용한다면 여전히 큰 순이익을 가져다줄 수 있다고 봅니다. HLSL이 C++을 따르기보다 다른 방향을 선택했어야 한다는 매우 합리적인 주장도 분명히 존재합니다…Slang의 제네릭 이 현재 가장 유용한 반례일 것입니다. 개인적으로 저는 대체로 실용주의자이며, 잘 이해되고 있는 기존 패러다임을 사용하는 데 큰 가치가 있다고 생각합니다. Slang의 차별화가 장기적으로 이득이 될지 확신하지 못합니다. 하지만 시간이 답을 줄 것이며, 그 분야에서 일어나는 일에 확실히 주목할 것입니다!
More Code Sharing Between HLSL and C++
많은 엔진들이 C++과 셰이더 코드 사이의 경계를 자동으로 관리하기 위해 상당한 양의 엔지니어링과 코드를 투자합니다. 이는 셰이더 리플렉션, 코드 생성 및/또는 런타임 레이어의 조합으로, 엔진 코드가 셰이더에 필요한 데이터와 바인딩을 제공할 수 있게 합니다. 이는 상당히 유용한 투자일 수 있습니다. 엔진이 바인딩이 작동하는 구체적인 세부 사항을 숨기거나, 심지어 기묘한 HLSL 상수 버퍼 정렬 규칙을 투명하게 설명할 수 있게 해주기 때문입니다. 그러나 이는 양날의 칼이 될 수 있습니다. 엔진에 특화된 난해한 특이점을 초래할 수 있으며, 새로운 기능 및/또는 API를 통해 이러한 레이어가 계속 작동하도록 유지하기 위해 상당한 유지 관리가 필요할 수 있습니다.
최근에는 HLSL과 C++ 간에 구조체, 함수 및 기타 코드를 공유하는 훨씬 단순한 방식에 끌리게 됩니다. 특히 최신 HLSL 언어 기능 덕분에 열거형, 템플릿, 메서드를 마음껏 사용할 수 있게 되어 이 방식이 더욱 용이해졌습니다. 무엇보다도 모든 것에 바인들리스(bindless)를 적용하면 이 방식이 훨씬 더 실현 가능해집니다. 앞서 언급했듯이, 바인들리스를 사용하면 모든 리소스 디스크립터를 32비트 정수나 핸들로 효과적으로 표현할 수 있으며, 이를 구조체에 자유롭게 저장할 수 있습니다. 이는 셰이더의 다양한 상수와 리소스를 C++과 HLSL 간에 공유하는 하나의 구조체에 간단히 저장할 수 있음을 의미하며, 코드 생성이나 리플렉션 없이도 C++과 HLSL 모두 최신 상태를 유지할 수 있습니다. 여기서 한 가지 주요한 문제는 상수 버퍼입니다. 안타깝게도 D3D12가 나온 지 10년이 지난 지금도 벡터와 배열에 대한 성가신 레거시 패킹 규칙이 여전히 남아 있습니다. 이러한 경우에는 정렬 문제를 수동으로 처리하거나 상수 버퍼를 아예 무시해야 합니다. 다행히 후자의 접근 방식은 현대 하드웨어에서 점점 더 실행 가능해지고 있습니다.
실제로 이 '단순 공유' 방식은 더 단순한 시나리오에서만 효과적일 가능성이 높습니다. 대규모 엔진은 더 복잡한 바인딩 메커니즘을 처리해야 할 것이며, 공유가 효과적이지 않은 특이한 플랫폼을 다뤄야 할 수도 있습니다. 따라서 만능 해결책은 아니지만, 점점 더 가치 있는 선택지가 되어가고 있다고 생각합니다.
Designated Initializers
이것은 그래픽스나 API와 직접적인 관련은 없지만, C++20의 지정 초기화자를 상당히 선호합니다. 구조체 멤버를 하나씩 설정하는 것보다 편리하며, 메서드 체이닝을 사용하는 "빌더" 패턴보다 컴파일러 및 비최적화 런타임 오버헤드가 적습니다. 저는 일반적으로 멤버 초기화자를 통해 기본값이 지정된 구조체와 함께 사용하는 것을 선호합니다. 그러면 지정 초기화자가 기본값을 "재정의"할 수 있죠. 이 패턴을 사용하면 매개변수 덩어리보다 훨씬 읽기 쉬운 명명된 인자도 에뮬레이트할 수 있습니다. 예를 들어:
struct RawBufferInit
{
uint64_t NumElements = 0;
bool32 CreateUAV = false;
bool32 Dynamic = false;
bool32 CPUAccessible = false;
const void* InitData = nullptr;
ID3D12Heap* Heap = nullptr;
uint64_t HeapOffset = 0;
const char* Name = nullptr;
};
spotLightClusterBuffer.Initialize({
.NumElements = numXYZTiles * AppSettings::SpotLightElementsPerCluster,
.CreateUAV = true,
.Name = "Spot Light Cluster Buffer",
});
제 경험상 이 방법은 리소스 초기화나 배리어 처리에도 아주 유용합니다. 저는 일반적인 배리어 상황을 처리해 주는 헬퍼를 먼저 준비한 다음, 지정된 초기화자를 사용해 세부 사항을 재정의하는 방식을 선호합니다:
struct DepthWritableBarrierDesc
{
bool FirstAccess = false;
bool Discard = false;
D3D12_BARRIER_SYNC SyncBefore = D3D12_BARRIER_SYNC_ALL_SHADING;
D3D12_BARRIER_ACCESS AccessBefore = D3D12_BARRIER_ACCESS_SHADER_RESOURCE;
D3D12_BARRIER_LAYOUT LayoutBefore = D3D12_BARRIER_LAYOUT_DIRECT_QUEUE_SHADER_RESOURCE;
uint32_t StartArraySlice = 0;
uint32_t NumArraySlices = uint32_t(-1);
};
DX12::Barrier(cmdList, depthBuffer.DepthWritableBarrier({ .FirstAccess = true }));
이제 제가 C++의 지정 초기화자 구현 방식에 대해 불평을 늘어놓을 차례입니다. 이 방식은 초기화자의 순서가 멤버 선언 순서와 일치해야 한다는 요구사항을 가지고 있죠. 이는 한 멤버의 초기화/생성이 다른 멤버에 의존하는 위험한 함정을 피하기 위해 설계된 방식입니다…하지만 이 특정 경계 사례가 초기화 순서를 신경 쓰지 않는 일반적인 99%의 경우에서 기능의 사용성을 저해한다는 점은 매우 안타깝습니다. Clang은 적어도 이를 경고로 낮출 수 있는 방법을 제공하지만, 제가 아는 한 MSVC는 그렇지 않습니다.
Printf and Other Shader Debug Features
다시 한번 말하지만, 이 작업은 최신 D3D와 HLSL 도구가 없어도 수행할 수 있습니다. 하지만 최신 버전을 사용한다면 훨씬 수월해집니다. 특히:
- SM 6.6 스타일 바인들리스를 사용하면 앱 코드 수정 없이도 모든 셰이더에서 전역적으로 쓰기 가능한 디버그 버퍼를 사용할 수 있습니다. 즉, 셰이더 핫 리로딩이 지원된다면 앱을 재시작하거나 재컴파일하지 않고도 셰이더에 디버그 출력 코드를 추가할 수 있습니다. 제 코드에서는 디버그 버퍼를 위해 디스크립터 힙 내 특정 알려진 인덱스를 예약하고, 이 인덱스를 셰이더가 디버그 기능을 위해 포함하는 .hlsli 파일에 하드코딩하여 이를 구현합니다.
- HLSL 템플릿과 RWByteAddressBuffer 타입 저장소는 이종 데이터를 디버그 버퍼에 넣는 작업을 훨씬 편리하게 만들어줍니다(printf 인수 같은 경우에 유용함).
- 공식 기능은 아니지만, DXC의 템플릿 기능을 (남용하여) 활용하여 실제 문자열 리터럴을 printf와 유사한 기능으로 사용할 수 있으며, 이는 다른 방법들보다 훨씬 간단하고 자연스럽습니다.
신뢰할 수 있는 셰이더 printf 기능은 게임 체인저가 될 수 있으며, PC에서의 디버깅 상황이 얼마나 끔찍한지 거의 잊게 만들 정도입니다. 제가 선호하는 방법은 특정 스레드로 디버깅 기능을 필터링할 수 있는 유틸리티 함수를 만드는 것입니다. 마우스 커서 아래 스레드/픽셀로 출력을 필터링하는 방식으로 구현할 수 있죠. 그런 다음 로컬 변수의 상태를 출력하는 헬퍼 매크로를 사용합니다. 이는 스레드에 대한 일종의 실시간 디버거 역할을 합니다. 이 설정을 완료하면 셰이더를 수정하면서 중간 변수의 값을 계속 확인하여 변경 사항의 최종 결과를 확인할 수 있습니다.
제가 최근에 자주 활용하는 또 다른 유용한 기법은 셰이더에서 직접 디버그 와이어프레임 형상을 그리는 것입니다. 이 과정은 셰이더 printf와 상당히 유사하게 시작됩니다: 전역적으로 접근 가능한 디버그 버퍼를 준비하고, 셰이더 함수가 형상 변환 및 속성을 해당 버퍼에 덤프합니다. 그런 다음 프레임 종료 직전에 각 형상에 대해 간접 드로우를 수행하여 디버그 버퍼의 데이터를 소비하고 화면에 형상을 그립니다. 모든 설정을 완료하려면 약간의 배관 작업이 필요하지만, 일단 작동하면 디버깅에 매우 유용할 수 있습니다. 또한 개발자 전용 디버그 시각화를 구현하는 상당히 편리한 방법이 될 수 있는데, 그렇지 않으면 CPU에서 수행하거나 맞춤형 셰이더를 사용해야 했을 것입니다. 예를 들어, 컴퓨트 셰이더에서 컬링을 수행하는 경우 컬링 작업 결과를 표시하기 위해 색상 경계 구체를 그릴 수 있습니다.
레이 생성 셰이더 디버깅을 위해 printf와 디버그 드로잉을 함께 사용하는 예시를 보여드리겠습니다. 이렇게 하면 제가 무슨 뜻인지 이해하실 수 있을 겁니다:
ShaderDebug::FilterIfCursorOnPos(pixelCoord);
DebugPrint_("RayGen Pixel XY: {0}", pixelCoord);
DebugPrintVar_(ray.Origin);
DebugPrintVar_(ray.Direction);
DebugPrintVar_(payload.HitT);
float3 arrowColor = payload.Radiance;
arrowColor/= max(max(max(arrowColor.x, arrowColor.y), arrowColor.z), 0.0001f);
float3 arrowEnd = ray.Origin + ray.Direction * payload.HitT;
ShaderDebug::DrawArrow(ray.Origin, arrowEnd, float4(arrowColor, 1.0f));
Conclusion
여기까지 읽어주셔서 감사합니다! 지난 10년간 D3D12에서 변경된 사항들의 범위를 어느 정도 파악하셨길 바라며, 제 개인적인 경험담도 흥미롭게 읽어주셨으면 합니다. 다음에 또 뵙겠습니다!